
‘R’(아르)는 통계계산과 그래픽을 위한 프로그래밍 언어이자 오픈소스 소프트웨어다. 무료로 배포되고 있으므로 상용 프로그램을 구입하지 않아도 사용할 수 있다. 무료라고 해서 기능이 약한 것도 아니다. R에서 활용할 수 있는 다양한 패키지가 개발돼 있으므로, 패키지를 내려받아 다양한 기능 확장을 꾀할 수 있다. 현재 공식적으로 등록된 패키지만 7600개 이상이다. 그 외에 깃허브에서 내려받을 수 있는 패키지까지 고려하면 활용할 수 있는 패키지는 2만개가 넘는 것으로 알려졌다.
R는 벨 연구소에서 개발된 S언어를 바탕으로 만들어졌으며, 뉴질랜드 오클랜드대학의 로스 이하카와 로버트 젠틀맨에 의해 시작됐다. 현재는 R 코어팀이 개발을 맡고 있다. 현재 3.2.3버전(우든 크리스마스 트리)까지 나왔다.
과거에는 SPSS 같은 유료 통계 프로그램이 많이 사용됐지만, 최근엔 R 같은 통계 언어로 자신의 입맛에 맞는 분석 결과물을 만드는 경우가 늘고 있다. 한때 SPSS는 대학 내 조사방법론 강의의 필수 코스로 여겨졌지만, 지금은 서서히 밀려나는 분위기다. R는 통계와 시각화에 특히 강점을 가지고 있고, 머신러닝 등에서도 활용된다.
확장성이 높은 R지만, R가 꼭 전문가만 쓸 수 있는 기술은 아니다. 프로그래밍 언어를 모르는 사람들도 R에 입문해 데이터를 다루는 경우가 종종 있다. 국내에서도 업계와 학계를 가리지 않고 널리 사용되고 있다.
통합 개발 환경, R스튜디오
R스튜디오 구동 화면
‘R스튜디오’는 R를 더 쉽게 다룰 수 있게 도와주는 일종의 통합 개발 환경이다. 프로젝트 관리에도 좋고, 함수에 대해 궁금한 점이 생긴다면 바로 도움이 되는 문서를 참조할 수 있는 점도 좋다. 훨씬 편리한 인터페이스를 제공한다.
R스튜디오를 실행하면 4분면으로 구분된 화면을 만날 수 있다. 스크립트, 콘솔, 환경과 기록, 파일관리, 플롯, 패키지 관리 등의 작업을 한 화면에서 수행할 수 있다. 코드를 짜다가 궁금한 함수의 사용법을 바로 찾아볼 수도 있고, 작업하면서 만들어 저장한 데이터도 확인할 수 있다.
스크립트는 코드를 짤 수 있는 공간이다. 따로 텍스트 편집기를 사용할 필요가 없이 프로젝트 단위로 관리할 수 있다. 기본 R 스크립트뿐만 아니라 R 마크다운 문서를 활용해 다양한 형태의 출력물(HTML, PDF, DOC)로 변환할 수도 있다.
특히 R 스튜디오에서는 도움말을 쉽게 확인할 수 있는 게 가장 큰 장점이다. 모르는 함수나 패키지 앞에서는 물음표(?)를 넣고 검색하면 참고문서를 확인할 수 있다. 비록 영어로 돼 있긴 하지만, 참고문서는 굉장히 자세한 편이다. 대략 다음과 같은 순서로 구성돼 있다.
• Description : 함수에 대한 개괄적인 설명
• Usage : 함수의 사용법
• Arguments : 함수가 가질 수 있는 인자들
• Value : 함수가 반환하는 값에 대한 설명
• Example : 함수가 실제로 사용된 예제코드
R 기본 개념과 말끔한 데이터
R의 데이터 타입은 크게 3가지다. 숫자형, 문자형, 논리형이다. 이 데이터를 몇 가지 형태로 묶어내 다룰 수 있다. 데이터가 묶이는 형태는 집합과 유사한 벡터, 행렬인 매트릭스, 표의 형태를 가진 데이터 프레임, 이런 형태를 한데 묶을 수 있는 리스트가 있다.
벡터는 동일한 타입의 데이터를 1개 이상 저장해둔 형태를 말한다. 하나의 벡터에는 하나의 타입만 들어갈 수 있다. 벡터는 ‘c()’라는 함수를 이용해 만들 수 있다. 이런 식이다.
new_vector = c(1,2,3,4,5)
매트릭스는 행과 열을 가지는 벡터다. 백터와 마찬가지로 같은 유형의 타입만 적용할 수 있다. ‘matrix(data =data, nrow = nrow, ncol = ncol, byrow = TRUE)’로 만들 수 있다. 행렬의 데이터에는 [행 번호, 열 번호]의 형태로 접근한다. 연산도 수행할 수 있다.
데이터 프레임은 흔히 접할 수 있는 자료와 유사한 형태다. 마치 엑셀에 그리는 표처럼 생겼다. 행렬처럼 행과 열의 길이가 일정하지만, 열마다 다른 형태의 자료를 담을 수 있다. 예컨대 <이름 : 홍길동, 나이 : 26, 참석여부 : T>의 데이터를 한 형태에서 사용할 수 있다. 일반적으로 가장 많이 활용하는 형태의 데이터다.
리스트는 위에 설명한 각종 형태의 데이터를 한데 묶고자 할 때 쓴다.
‘말끔한 데이터’(Tidy Data)는 통계학자 헤들리 위컴이 제시한 개념이다. 간단히 설명하자면 하나의 변수는 하나의 열을 구성해야 하고, 각 관측치는 하나의 행을 구성하며, 하나의 값은 단 하나의 의미만 있어야 깔끔하게 사용할 수 있다는 내용이다. 좀 더 쉽게 이해하기 위해 다음 표를 보자.

세 사람이 시간별로 페이스북에 몇 번 접속하는지 횟수를 나타낸 데이터다. 예시를 위해 임의로 지어낸 데이터다. 보기엔 그렇게 너저분해 보이진 않지만, 데이터를 추가하려고 하면 문제가 생긴다. 예컨대 트위터나 네이버 블로그의 접속도 표시한다면 가로로 쭉 길어지는 형태가 되고 만다. 값만 추가할 수도 없게 된다. 이는 관측치가 하나의 의미만 있지 않기 때문이다. 예컨대 A의 15시 페이스북 접속횟수를 나타내는 ‘13’의 경우는 접속 횟수와 접속한 시간(15시)이라는 의미를 모두 갖고 있다.
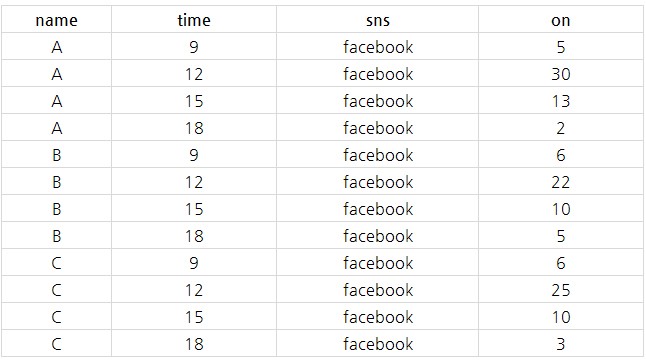
반면, 이렇게 정리된 데이터는 컴퓨터가 읽기 좋은 데이터다. 양이 많아진 것 같지만, 이렇게 데이터를 정리할 경우 앞으로 추가되는 데이터를 반영하기에 훨씬 수월하다.
R에서 많이 활용하는 패키지의 함수를 활용하려면 이런 긴 형태의 데이터(long form)가 더 적합하다. 비단 R가 아니더라도 말끔한 데이터를 만드는 게 활용하기에 좋다. 말끔한 데이터는 데이터베이스의 정규화로 데이터의 중복을 피할 수 있다는 장점도 가지고 있다. 말끔한 데이터를 만들기 위해 엑셀에서 일일이 수정할 필요는 없다. R에서 활용할 수 있는 ‘reshape’ 패키지를 활용하면 필요에 따라 재배치할 수 있다. ‘melt()’ 함수를 활용하면 된다.
R에서 사용하면 유용한 패키지
R는 패키지 설치를 통해 기능확장을 구현할 수 있다. 기본적으로 제공하는 기능이라고 하더라도, 패키지를 활용하면 더 효율적인 경우도 있다. 유용한 패키지는 매우 많다. 데이터 조작에 사용되는 ‘디플라이아르(dplyr)’, 데이터 시각화에 사용되는 ‘지지플롯2(ggplot2)’, 동적인 표를 생성할 수 있는 ‘아르차트(rCharts)’, 데이터 수집에 사용되는 ‘아르베스트(rvest)’, R로 웹앱을 구현할 수 있는 ‘샤이니(shiny)’가 있다. 그중 가장 많이 사용되고 있는 디플라이아르와 지지플롯2의 기본적인 활용에 대해 알아보자.

R 치트시트
디플라이아르의 함수들은 데이터 조작에 효율적이다. 데이터를 정제하고 원하는 대로 조합하고, 연산을 수행할 수 있다. 주요 함수의 기능은 다음과 같다.
– select 함수 : select 함수는 임의의 열을 선택한다. 열의 순서도 바꿀 수 있다. ‘select(데이터, 열 이름, 열 이름)’의 형식으로 사용한다. 열 이름은 ‘새로운 이름 = 기존 이름’ 으로 바꿀 수도 있다.
– filter 함수 : 조건을 지정해서 원하는 행만 출력할 수 있다. 연산자들 통해 ‘or 연산’을 수행할 수 있다. ‘and연산’은 조건을 그냥 쉼표(,) 로 이어 붙이면 된다. 예컨대 데이터에서 어떤 학교의 정보만 가져오고 싶다면 ‘filter(데이터, 학교 == ‘A 대학교’)’를 사용할 수 있다. A 대학이나 B 대학의 정보를 가져오고자 한다면 ‘filter(데이터, 학교 == ‘A 대학교’ | 학교 == ‘B 대학교’)’로 쓰면 된다.
– mutate 함수 : 새로운 열을 생성하는 함수다. 함수 내에서 생성한 열도 바로 연산으로 사용할 수 있다. 성적 데이터가 있다고 가정했을 때 전체 평균 데이터를 추가해서 붙이고 싶다면 ‘mutate(데이터, 새로 추가할 데이터 이름 = 연산 결과물)’을 이용하면 된다. 함수와 연산을 이용해서 데이터를 가공해 새로 추가하기에 좋다. 차이나 변화량을 알고 싶을 때 연산을 이용해 새로운 열을 추가할 수 있다.
– group_by 함수 : 그룹을 묶어주는 함수다. 실제로 묶는 건 아니다. 연산에만 사용되는 그룹이다. 예컨대 시간 데이터가 있다면 간격을 두고 시간 단위로 묶어낼 수도 있다. 소속이나 범주 등도 묶을 수 있다.
– summary 함수 : 데이터를 요약한다. 그룹이 지정된 경우는 그룹별 요약을 출력한다. 지정되지 않은 경우는 1행짜리 결과물이 출력된다.
– arrange 함수 : 지정한 열을 기준으로 데이터를 정렬한다. 기본은 오름차순이다. ‘desc()’를 입력하면 내림차순으로 정렬한다.
– top_n 함수 : ‘top_n(n = 출력할 개수, wt = 지정변수)’를 쓰면 지정한 변수를 기준으로 상위 n 개까지 출력한다. 그룹이 지정돼 있으면 그룹별로 n개씩 출력한다.
보통 코딩을 할 때는 데이터와 먼저 처리해야 하는 함수가 가장 안쪽에, 그다음 처리하는 함수가 다음 바깥쪽, 마지막에 처리해야 하는 함수가 가장 바깥쪽에서 나머지를 감싸고 있는 형태다. 이렇게 함수를 중첩해서 사용하게 되면 보기도 복잡하고 어디서 틀렸는지 찾아내기도 어렵다. 그렇다고 함수를 하나씩 적용하고 변수로 만들어 넘기는 일도 복잡하다. 이를 해결하기 위해 사용하는 게 ‘파이프 연산자’다. 먼저 처리해야 하는 것을 앞에 쓰고 순차적으로 이어지는 과정이 생각하는 흐름과 유사하게 진행된다. 보기에도 깔끔하다. 디플라이아르에서는 파이프 연산자를 활용하면 효율적으로 코드를 짤 수 있다.
지지플롯과 리플렛js를 함께 활용한 그래프
R에서도 기본적인 그래프를 지원한다. 그러나 간편하게 그릴 수 있지만 대충 어떤 형태인지 알아보기에 적합한 수준이다. 제대로 분석을 하기 위해서는 ‘지지플롯2’라는, 그래프에 특화된 패키지를 이용할 필요가 있다. 지지플롯2는 다양한 형태의 그래프를 지원한다. 관련 치트시트를 보면 어떤 상황에서 어떤 그래프를 활용할 수 있는지 확인할 수 있다. 사용할 변수가 하나일 때와 둘, 셋일 때 사용하면 좋은 그래프가 구분돼 있다.
지지플롯2는 하나 이상의 레이어가 구성되면 그래프를 출력한다. ‘하나 이상’이라는 말은 여러 개의 레이어를 중첩할 수도 있다는 의미다. 레이어 이외에 그래프를 구성하는 요소는 데이터의 값이 그래프의 시각적 요소에 적용되는 과정을 조절하는 ‘Scale’, 좌표를 결정하는 시각적 요소가 어떻게 연결되는지 결정하는 ‘CoordinateSystem’, 데이터를 여러개의 그래프로 표시할 수 있게 하는 ‘Facet’, 그래프의 시각적 속성이 어떻게 데이터와 연관되는지 안내하는 ‘Guide’가 있다.
하지만 구체적으로 각 요소를 조절할 게 아니라면 이런 식으로는 잘 사용하지 않는다. 실제로 사용할 때는 자주 사용하는 요소를 묶어서 미리 만든 함수들을 활용한다. 미리 공통적인 요소를 ‘ggplot()’ 함수 안에 설정하고 레이어를 더하는 식으로 사용한다.
지지맵이나 리플렛js 패키지를 활용하면 지도와 함께 그래프를 활용할 수도 있다. 결과물은 이미지로 출력할 수도 있고, 리플렛js는 인터랙티브한 지도로 출력할 수 있다.
R를 배우려면
데이터캠프 화면 갈무리
R는 다양한 방법으로 배울 수 있다. 영어가 어렵지 않다면, 공식 문서만 참고해도 어느 정도는 배울 수 있다. 데이터캠프 사이트에서 튜토리얼을 진행하며 강의를 듣는 것도 좋은 방법이다. 간단하게 함수의 사용법을 설명한 공식 치트시트를 참고해도 좋다. 치트시트는 영어를 잘 못 해도 그림으로 설명을 보조하기 때문에 이해가 어렵지 않다.
한국어로 공부한다면 책이나 블로그, 커뮤니티를 참고하면 좋다. 많진 않지만 온라인에 커뮤니티에서도 이야기를 하고 있고, 블로그에 정리된 글도 꽤 있다. 시중에 교재를 구입해 공부하는 것도 좋은 방법이다.[more…]